AI and Written Description: When Does an AI Patent Claim Cross the Line?
June 28, 2021
Following Ed Garlepp’s great discussion on AI disclosure issues[1][2], I want to describe a related problem with AI and issues arising under the written description requirement that I often bring up when presenting on this topic. I started raising this topic following an episode of HBO’s Silicon Valley. One of the characters who lives in the incubator depicted in the show, Jian Yang, pitches an app to venture capitalists called “See Food” which is described as a “Shazam for food.” The user takes a picture of food, and then the app returns an identification of the food. Eventually Jian Yang does come up with an app that can identify food. The problem: it can only identify “hot dog” and “not hot dog.” When asked why he only created an app that only recognizes one type of food, Jian Yang explains that identifying more foods will require scraping significantly more images of food from the Internet to use as training data for a computational model.
Being a patent lawyer, I imagined what a claim may look like if Jian Yang applied for the patent. For instance, hypothetical original Claim 1 may be as follows.
1. A method, implemented by a computer, comprising:
capturing an image of a food item; and
outputting identification of the food item based on features included in the image.
Do you see the problem? We already know that Jian Yang has only created an app that can identify whether or not one type of food (i.e., hot dog) is in the image, but his claim is covering an invention that can identify any type of food. For the purposes of this hypothetical, let us assume that Jian Yang’s disclosed technique and examples are only applicable for identifying a hot dog. This potentially raises a problem under 35 U.S.C. §112(a) as failing to meet the written description requirement.
As explained in the U.S. Manual of Patent Examining Procedure (MPEP §2163)[3]:
“The Federal Circuit has explained that a specification cannot always support expansive claim language and satisfy the requirements of 35 U.S.C. 112 "merely by clearly describing one embodiment of the thing claimed." LizardTech v. Earth Resource Mapping, Inc., 424 F.3d 1336, 1346, 76 USPQ2d 1731, 1733 (Fed. Cir. 2005). The issue is whether a person skilled in the art would understand applicant to have invented, and been in possession of, the invention as broadly claimed.
…Satisfactory disclosure of a "representative number" depends on whether one of skill in the art would recognize that the applicant was in possession of the necessary common attributes or features possessed by the members of the genus in view of the species disclosed. For inventions in an unpredictable art, adequate written description of a genus which embraces widely variant species cannot be achieved by disclosing only one species within the genus.”
So Jian Yang’s claim would not comply with 35 U.S.C. §112(a) if the specification did not support such an expansive claim. However, in the real world, it may not be clear when a claim fails to meet the written description requirement. As noted by the Federal Circuit, the level of detail required to satisfy the written description requirement varies depending on the nature and scope of the claims and on the complexity and predictability of the relevant technology.[4] In many cases, a specification may include one or two examples coupled with a teaching of a method that could apply to other examples not explicitly described in the specification. This is a difficult and sometimes subjective task being asked of a patent examiner when he/she is presented with broad claims. However, in the AI realm, where recognition of a broad number of objects in a particular field is the ultimate goal of many inventors, it is important to ensure that broad claims are scrutinized properly.
Japan similarly has recognized that inadequate description problems can arise in AI applications. In 2019, the Japan Patent Office (JPO) created case examples for AI- related technologies which emphasized the description requirement.[5] In the training, the JPO presented the following example claims (Case Example 49).
[Claim 1] A body weight estimation system comprising:
a model generation means for generating an estimation model that estimates a body weight of a person based on a feature value representing a face shape and a body height of the person, through machine learning using training data containing feature values representing face images as well as actual measured values of body heights and body weights of people;
a reception means for receiving an input of a face image and body height of a person;
a feature value obtainment means for obtaining a feature value representing a face shape of the person through analysis of the face image of the person that has been received by the reception means; and
a processing means for outputting an estimated value of a body weight of the person based on the feature value representing the face shape of the person that has been received by the feature value obtainment means and the body height of the person that has been received by the reception means, using the generated estimation model by the model generation means.
[Claim 2] The body weight estimation system as in Claim 1, wherein the feature value representing a face shape is a face-outline angle.
In this JPO example (see below), the inventor found a statistically significant correlation between a cosine of a face-outline angle and BMI (defined as a body weight divided by the square of a body height) of a person. With this correlation, it is possible to estimate a person’s body weight based on the face outline features and body height of a person.
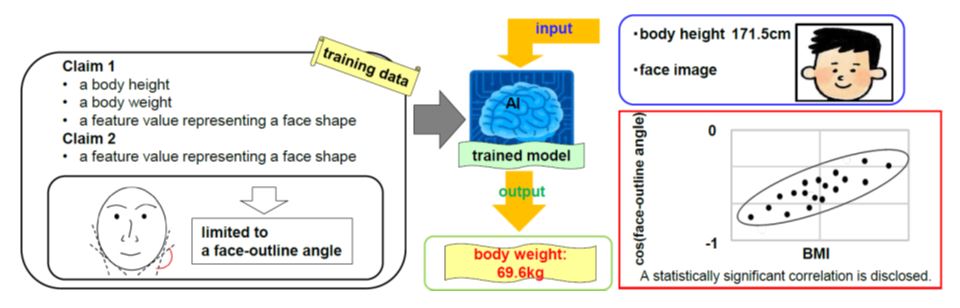
The JPO advised that Claim 1 should be refused, but Claim 2 was acceptable. Specifically, the description did not disclose a correlation between a feature value other than a face-outline angle. The JPO states “In other words, the scope of the description cannot be expanded or generalized to that of the invention of Claim 1, in which an input to an estimation model that outputs an estimation value of a body weight is specified only by a body height and a feature value representing a face shape in a face image of a person. …, it does not seem that a person skilled in the art can make a body weight estimation system that estimates a body weight of a person in response to an input of a body height and a feature value representing a face shape of a person, by generating an estimation model using a universal machine learning algorithm with a training data containing actual measured values of body weights, body heights, and feature values representing face shapes of people.”
What I found interesting about this example is that the language that was objected to was “a feature value representing a face shape.” This illustrates how AI can represent a challenge for obtaining a patent with a broad scope while also meeting the description requirement of a particular country’s patent laws. It also stresses the importance of using the dependent claims in a way that can hedge against potential issues in the independent claims.
Thus, AI can sometimes be viewed as the synthesis of correlations and predictions. However, a patent claim may allow an inventor or company to gain legal protection of a tenuous synthesis of a correlation and prediction. This can have huge implications in the tech industry as huge investment goes into realizing a high quality AI tool in the practical world. Thus, patent systems worldwide need to ensure that any issued patents in this area are not over-reaching in their scope. Also, patent practitioners need to be aware of (1) how to spot potential issues in an invention disclosure when drafting an application and (2) where the margins may lie when generating a claim set.
[1] https://www.theaipatentblog.com/disclosing-ai-inventions-part-i-identifying-the-unique-disclosure-issues
[2] https://www.theaipatentblog.com/disclosing-ai-inventions-part-ii-describing-and-enabling-ai-inventions
[4] Ariad Pharm., Inc. v. Eli Lilly & Co, 598 F.3d 1336, 1351 (Fed. Cir. 2010)
[5] https://www.jpo.go.jp/e/system/laws/rule/guideline/patent/document/ai_jirei_e/jirei_tsuika_e.pdf